Manatee overview
This document provides basic instruction on the Triton Manatee data store.
What is Manatee?
Manatee is an automated failover, fault monitoring and leader-election system built for managing a set of replicated Postgres servers. It is written completely in Node.js.
A traditional replicated Postgres shard is not resilient to the death or partition of any of the nodes from the rest. This is generally solved by involving a human in the loop, such as having monitoring systems which alerts an operator to fix the shard manually when failure events occur.
Manatee automates failover by using a consensus layer (Zookeeper) and takes the human out of the loop. In the face of network partitions or death of any node, Manatee will automatically detect these events and rearrange the shard topology so that neither durability nor availability are compromised. The loss of one node in a Manatee shard will not impact system read/write availability, even if it was the primary node in the shard. Reads are still available as long as there is at least one active node left in the shard. Data integrity is never compromised -- Manatee has built in data divergence detection and will prevent data on the nodes from forking from each other.
Manatee also simplifies backups, restores and rebuilds. New nodes in the shard are automatically bootstrapped from existing nodes. If a node becomes unrecoverable, it can be rebuilt by restoring from an existing node in the shard.
Architectural components
Shard overview
This is the component diagram of a fully setup Manatee shard. Much of the details of each Manatee node itself has been simplified, with detailed descriptions in later sections.
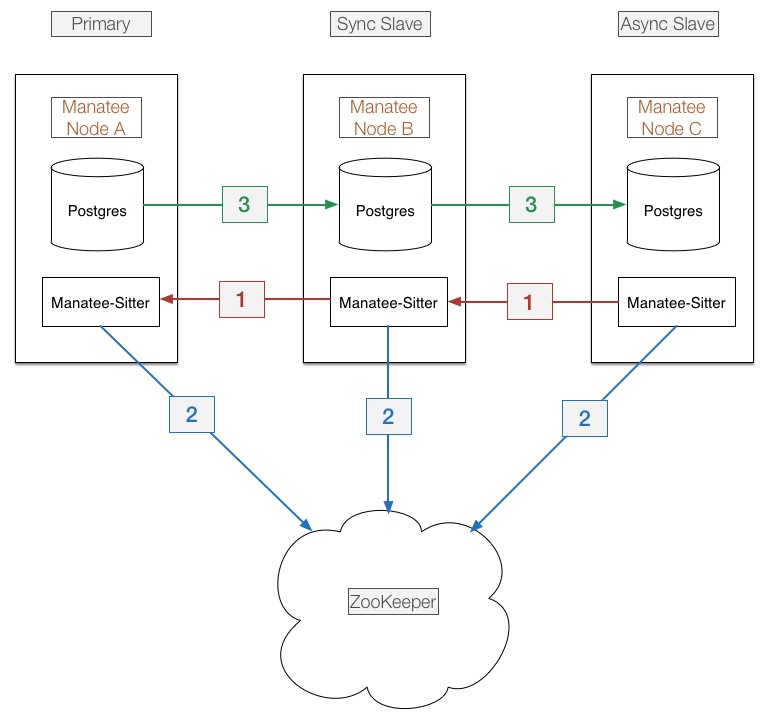
Each shard consists of 3 Manatee nodes, a primary(A), synchronous standby(B) and asynchronous standby(C) setup in a daisy chain. Nodes only gossip to other nodes that are immediately adjacent in the graph. Using node A as an example, it is only aware of the node directly in front of it (none) and the node directly behind it, B.
PostgreSQL Cascading Replication is used in the shard at (3). There is only one direct replication connection to each node from the node immediately behind it. That is, only B replicates from A, and only C replicates from B. C will never replicate from A as long as B is alive.
The primary uses PostgreSQL synchronous replication to replicate to the synchronous standby. This ensures data written to Manatee will be persisted to at least the primary and sync standby. Without this, failovers of a node in the shard can cause data inconsistency between nodes. The synchronous standby uses asynchronous replication to the async standby.
The topology of the shard is maintained by (1) and (2). Leaders of each node, (i.e. the node directly in front of self) are determined by (2) via Zookeeper(ZK). Standbys are determined by the standby node itself, the standby in this case B, determines via (2) that its leader is A, and communicates its standby status to A via (1).
When a node dies, the node that's directly behind it is promoted in the topology. If the promoted node was an async peer and is promoted to the sync peer, it's Postgres replication type is also changed from async to sync.
Manatee node detail
Here are the components encapsulated within a single Manatee node.
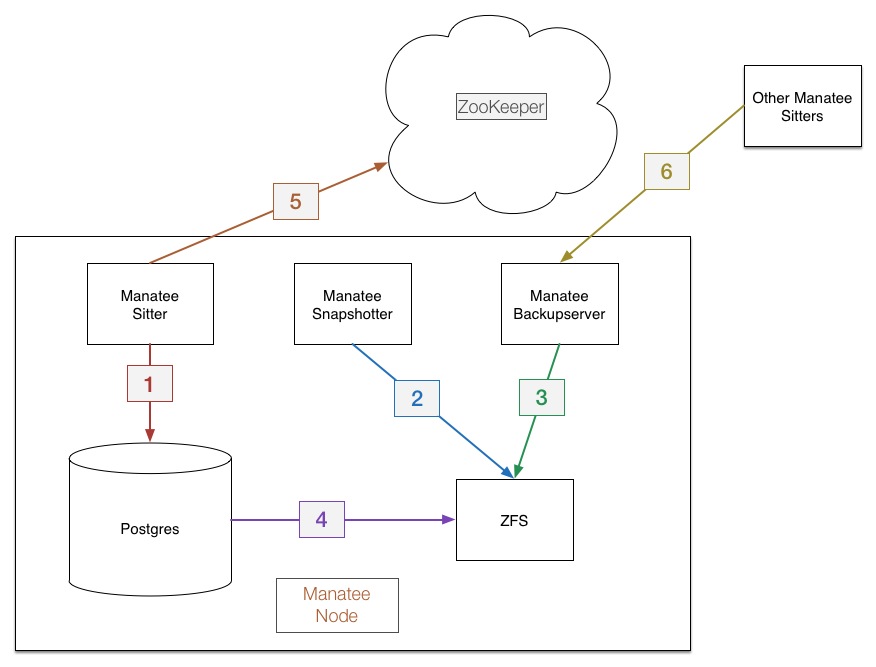
Manatee sitter
The sitter is the main process in within Manatee. The Postgres process runs as the child of the sitter. Postgres never runs unless the sitter is running. The sitter is responsible for:
- Managing the underlying Postgres instance. The Postgres process runs as a child process of the sitter. This means that Postgres doesn't run unless the sitter is running. Additionally, the sitter initializes, restores, and configures the Postgres instance depending on its current role in the shard. (1)
- Managing leadership status with ZK. Each sitter participates in a ZK election, and is notified when its leader node has changed. (5)
- ZFS is used by Postgres to persist data (4). The use of ZFS will be elaborated on in a later section.
Manatee snapshotter
The snapshotter takes periodic ZFS snapshots of the Postgres instance. (2) These snapshots are used to backup and restore the database to other nodes in the shard.
Manatee backup server
The snapshots taken by the snapshotter are made available to other nodes by the REST backupserver. The backupserver, upon receiving a backup request, will send the snapshots to another node. (3) (6)
ZFS
Manatee relies on the ZFS file system. Specifically, ZFS snapshots are used to create point-in-time snapshots of the Postgres database. The zfs send and zfs recv utilities are used to restore or bootstrap other nodes in the shard.
Shard administration
Manatee provides the manatee-adm utility which gives visibility into the status of the Manatee shard. One of the key subcommands is the status command.
[root@host ~/manatee]# ./node_modules/manatee/bin/manatee-adm status -z <zk_ip>
{
"1": {
"primary": {
"ip": "172.27.4.12",
"pgUrl": "tcp://postgres@172.27.4.12:5432/postgres",
"zoneId": "b515b611-3b6e-4cc9-8d1f-3cf78e27bf24",
"repl": {
"pid": 23047,
"usesysid": 10,
"usename": "postgres",
"application_name": "tcp://postgres@172.27.5.8:5432/postgres",
"client_addr": "172.27.5.8",
"client_hostname": "",
"client_port": 42718,
"backend_start": "2014-04-28T17:07:55.548Z",
"state": "streaming",
"sent_location": "E/D9D14780",
"write_location": "E/D9D14780",
"flush_location": "E/D9D14780",
"replay_location": "E/D9D14378",
"sync_priority": 1,
"sync_state": "sync"
}
},
"sync": {
"ip": "172.27.5.8",
"pgUrl": "tcp://postgres@172.27.5.8:5432/postgres",
"zoneId": "d2de0030-986e-4dae-991d-7d85f2e333d9",
"repl": {
"pid": 95136,
"usesysid": 10,
"usename": "postgres",
"application_name": "tcp://postgres@172.27.3.7:5432/postgres",
"client_addr": "172.27.3.7",
"client_hostname": "",
"client_port": 53461,
"backend_start": "2014-04-28T21:28:07.905Z",
"state": "streaming",
"sent_location": "E/D9D14780",
"write_location": "E/D9D14780",
"flush_location": "E/D9D14780",
"replay_location": "E/D9D14378",
"sync_priority": 0,
"sync_state": "async"
}
},
"async": {
"ip": "172.27.3.7",
"pgUrl": "tcp://postgres@172.27.3.7:5432/postgres",
"zoneId": "70d44638-f4fb-4cbd-8611-0f7c83d8502f",
"repl": {},
"lag": {
"time_lag": {}
}
}
}
}This prints out the current topology of the shard. The repl field shows the standby that's currently connected to the node. It's the same set of fields that is returned by the Postgres query select * from pg_stat_replication. The repl field is helpful in verifying the status of the PostgreSQL instances. If the repl field exists, it means that the node's standby is caught up and streaming. If there is no repl field, it means that there is no Postgres instance replication from this node. This is expected with the last node in the shard.
However, if there is another node after the current one in the shard, and there is no repl field, it indicates there is a problem with replication between the two nodes.
Shard history
You can query any past topology changes by using the history subcommand.
[root@host ~/manatee]# ./node_modules/manatee/bin/manatee-adm history -s '1' -z <zk_ips>
{"time":"1394597418025","date":"2014-03-12T04:10:18.025Z","ip":"172.27.3.8","action":"AssumeLeader","role":"Leader","master":"","slave":"","zkSeq":"0000000000"}
{"time":"1394597438430","date":"2014-03-12T04:10:38.430Z","ip":"172.27.4.13","action":"NewLeader","role":"Standby","master":"172.27.3.8","slave":"","zkSeq":"0000000001"}
{"time":"1394597451091","date":"2014-03-12T04:10:51.091Z","ip":"172.27.3.8","action":"NewStandby","role":"Leader","master":"","slave":"5432","zkSeq":"0000000002"}
{"time":"1394597477394","date":"2014-03-12T04:11:17.394Z","ip":"172.27.5.9","action":"NewLeader","role":"Standby","master":"172.27.4.13","slave":"","zkSeq":"0000000003"}
{"time":"1394597473513","date":"2014-03-12T04:11:13.513Z","ip":"172.27.4.13","action":"NewStandby","role":"Standby","master":"172.27.3.8","slave":"5432","zkSeq":"0000000004"}
{"time":"1395446372034","date":"2014-03-21T23:59:32.034Z","ip":"172.27.5.9","action":"NewLeader","role":"Standby","master":"172.27.3.8","slave":"","zkSeq":"0000000005"}
{"time":"1395446374071","date":"2014-03-21T23:59:34.071Z","ip":"172.27.3.8","action":"NewStandby","role":"Leader","master":"","slave":"5432","zkSeq":"0000000006"}
{"time":"1395449937712","date":"2014-03-22T00:58:57.712Z","ip":"172.27.4.13","action":"NewLeader","role":"Standby","master":"172.27.5.9","slave":"","zkSeq":"0000000007"}
{"time":"1395449938742","date":"2014-03-22T00:58:58.742Z","ip":"172.27.5.9","action":"NewStandby","role":"Standby","master":"172.27.3.8","slave":"5432","zkSeq":"0000000008"}
{"time":"1395450121000","date":"2014-03-22T01:02:01.000Z","ip":"172.27.5.9","action":"NewLeader","role":"Standby","master":"172.27.4.13","slave":"","zkSeq":"0000000009"}
{"time":"1395450121005","date":"2014-03-22T01:02:01.005Z","ip":"172.27.5.9","action":"NewStandby","role":"Standby","master":"172.27.4.13","slave":"5432","zkSeq":"0000000010"}
{"time":"1395450121580","date":"2014-03-22T01:02:01.580Z","ip":"172.27.4.13","action":"NewLeader","role":"Standby","master":"172.27.3.8","slave":"","zkSeq":"0000000011"}
{"time":"1395450122033","date":"2014-03-22T01:02:02.033Z","ip":"172.27.4.13","action":"NewStandby","role":"Standby","master":"172.27.3.8","slave":"5432","zkSeq":"0000000012"}This will return a list of every single Manatee flip sorted by time. The node is identified by the "ip" field. The type of transition is identified by the "action" field. The current role of the node is identified by the "role" field. Only the first element of the daisy chain, i.e. the Primary node, will ever have the role of Leader. All other nodes will be standbys.
There are 3 different types of Manatee flips:
AssumeLeader. This means the node has become the primary of the shard. This might mean that the primary has changed. Verify against the last AssumeLeader event to see if the primary has changed.NewLeader. This means the current node's leader may have changed. the "master" field represents its new leader. Note that its leader may not necessarily be the primary of the shard, it only represents the node directly in front of the current node.NewStandby. This means the current node's standby may have changed. The "slave" field represents the new standby node.
This tool is invaluable when attempting to reconstruct the timeline of flips in a Manatee shard, especially when the shard is in safe mode.
Safe mode
You can check that the shard is in safe mode via manatee-adm status.
[root@host ~/manatee]# ./node_modules/manatee/bin/manatee-stat -p <zk_ip>
{
"1": {
"error": {
"primary": "172.27.4.12",
"zoneId": "8372b732-007c-400c-9642-9eb63d169cf2"
}
}
}The error field indicates that the shard is in safe mode.
When in safe mode, Manatee will be only available for reads but you will not be able to write to it until it is manually cleared by an operator.
Before we run through how to bring a Manatee back up from safe mode, it's important to discuss why safe mode exists.
There are situations through a series of Manatee flips where the shard's data could potentially become inconsistent. Consider the following scenario: We have a Manatee shard at rest with nodes A, B, and C. Refer to the Shard Overview section for the diagram of this topology.
Now, imagine that all 3 nodes restart at around the same time. If C enters the shard first, it becomes the primary of the shard. Because it was previously the async, its Postgres xlog may not be completely up to date. If C starts taking writes at this point then the data between C, and A/B will become forked and the shard has become inconsistent.
Manatee will not allow this to happen. The shard will enter safe mode if detects a mismatch between the primary and its standby's xlogs.
In practice this situation could occur frequently, e.g. in the face of network partitions. Instead of taking a 33% chance each time this happens that the shard will enter safe mode (if the async gets promoted to primary), Manatee proactively tries to avoid this by persisting information about the previous topological state. Only the previous primary or sync can be promoted to the primary.
However, due to some limitations in Postgres itself, this is sometimes not sufficient. In this case, the shard will detect that it can no longer take writes and put itself into safe mode.
Troubleshooting
As mentioned above, a shard that has gone into safe mode will require operator intervention to recover. For detailed instructions on how to accomplish this, please see the page Troubleshooting manatee